time_remain是实现倒计时效果,但是如何把它固定在一行的指定区域呢? 不干扰其他区域的显示呢?最后输出这样的信息,最右边的是总时长,但是倒计时效果出现在最左边,如果不预留 ' '...
关于python报错“IOError: [Errno 22] Invalid argument”
今天使用python进行文本操作时,时常出现IOError: Invalid argument报错排查了下:读取文件路径使用如c:\\1.txt或c:/1.txt;对写入内容进行strip()在对异常...
 Python
Python
python爬取网页中javascript动态添加的内容(一)
这几天刚好在学Requests和BeautifulSoup结合做爬虫爬取网页内容,恰巧有个哥们在群里问select函数里应该怎么来填?我想也是我在学,不妨找他一起做做,如果能帮人那最好不过啦。好吧,进...
python获取完整网页内容(即包括js动态加载的):selenium+phantomjs
在上一篇文章(http://blog.csdn.net/Trisyp/article/details/78732630)中我们利用模拟打开浏览器的方法模拟点击网页中的加载更多来实现动态加载网页并获取网...
python—cookielib模块对cookies的操作
python内置有cookielib模块操作cookie,配合urllib模块就可以了很轻易的爬取数据。 #encoding:utf8import urllib2import cookiel...
Python实现从文件中读取指定行的方法
这篇文章主要介绍了Python3实现从文件中读取指定行的方法,涉及Python中linecache模块操作文件的使用技巧,需要的朋友可以参考下本文实例讲述了Python3实现从文件中读取指定行的方法。...
Windows+Python 3.6环境下安装PyQt4
只针对windows环境下的Python3.6版本而言的,而且注意要安装的是PyQt4,而不是PyQt5。为什么要强调这个,是因为大家如果用过Python的第三方绘图库matplotlib和seabo...
 Python
Python
python中的正则表达式(re模块)
一、简介正则表达式本身是一种小型的、高度专业化的编程语言,而在python中,通过内嵌集成re模块,程序媛们可以直接调用来实现正则匹配。正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执...
 Python
Python
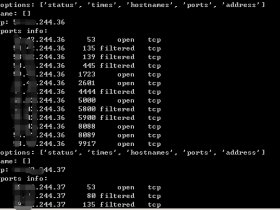
用python解析nmap的扫描xml结果文件
对nmap扫描结果xml格式的文件进行解析,无需直接xml解析或读取,可直接使用模块:1.nmapparser安装:pip install nmapparserDemo:#!/usr/bin...
 Python
Python
Python——Output not utf-8错误解决办法
(经站长测试未成功,其他人可以试试)SublimeText是一款可以支持多种程序语言的代码编写软件,支持代码的缩进、高亮、代码补全等功能,使用起来比较方便。SublimeText3可以在网上下载,较绿...
