Python windows安装tesseract-ocr 一、安装步骤 双击tesseract-ocr-w64-setup-5.3.4.20240503.exe 安装包,点击ok 点击【Next】 点击【I Agree】 点击【N... 08月13日 1,118 次浏览 发表评论 阅读全文
基于grpc的流式方式实现双向通讯(python) 这篇文章介绍了通过grpc的流式通信方式实现双向通讯的方法. grpc介绍 grpc是谷歌开源的一套基于rpc实现的通讯框架(官网有更完整的定义)。在搞懂grpc之前,首先要弄懂rpc是什么。下面是自... 03月07日 Python 1,035 次浏览 发表评论 阅读全文
python操作TFS的Work Item 因工作需要,现需要将jira切换到微软的TFS(Team Foundation Server),并自动化创建TFS的任务(即 Work Item)。根据该需求,我首先使用了它的REST API进行尝试... 03月07日 Python 829 次浏览 发表评论 阅读全文
PyQt开发(三):Events与Signals 4月 23, 2018 1条评论 7,283次阅读 1人点赞 0x00 前述 在写PyQt的时候,会发现由于UI线程是独立的,因此我们不能够在其他逻辑线程中,直接去对UI进行操作。而PyQt给我们提供... 01月05日 Python 525 次浏览 发表评论 阅读全文
PyQt开发(二):界面与逻辑分离 0x00 PyQt原生支持界面与逻辑分离,特别是使用QtDesigner设计界面。 0x01 转换UI文件 使用QtDesigner设计并保存界面之后,会产生一个.ui文件,这里我们使用PyUIC去直... 01月05日 Python 442 次浏览 发表评论 阅读全文
Python PyQt开发(一):环境配置(PyCharm) 0x00 毕设项目需要用Python实现一个GUI界面,在查询了一番之后我选择了PyQt。 0x01 环境 Python 3.6.1, PyCharm 2018.1 0x02 安装PyQt 在这里,推... 01月05日 367 次浏览 发表评论 阅读全文
Python:类内装饰器的使用(pymongo自动重连实现) | 心 空 0x00 最近要实现一个pymongo库的自动重连功能,但是官方文档只说了: In order to auto-reconnect you must handle this exception, re... 01月05日 Python 368 次浏览 发表评论 阅读全文
Python 内存分析杂记 7月 29, 2019 1条评论 6,080次阅读 0人点赞 Tracemalloc Python 3.4里引入的一个专门用来分析内存状态的模块。tracemalloc 这里我们只需要记住几个命令就行... 01月05日 Python 367 次浏览 发表评论 阅读全文
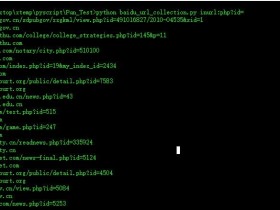
Python 百度搜索结果爬虫 1. 目的 使用爬虫脚本 爬去 百度搜索关键字后获得链接地址以及域名信息 可结合GHDB语法 e.g. inrul:php?id= 2. 知识结构 2.1 使用 thread... 12月31日 513 次浏览 发表评论 阅读全文
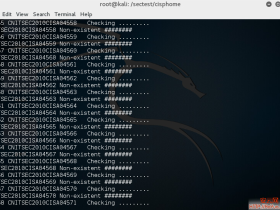
Python BS4爬虫实例应用-CISP 爬取目前在官网可查询的CISP证书编号以及有效期并入库 也算是暴力破解,burp使用grep功能呢也可以实现。 下面是python的代码 #coding=utf-8 import requests i... 12月31日 447 次浏览 发表评论 阅读全文
 Python
Python
Python
Python
 Python
Python
 Python
Python
 Python
Python
