- A+
所属分类:系统文档

<!DOCTYPE html>
<html>
<head>
<title> 获取网页内容示例 </title>
</head>
<body>
<div id="content"></div>
<script>
const contentDiv = document.getElementById('content');
// 要获取内容的网页的 URL
const url = 'https://example.com'; // 将这里的 url 改为自己的
// 使用 fetch API 获取网页内容
fetch(url)
.then(response => {
// 将响应数据转换为文本
return response.text();})
.then(data => {
// 在这里处理响应数据
contentDiv.textContent = data;
})
.catch(error => {
// 在这里处理错误
console.error('获取内容发生错误:', error);
});
</script>
</body>
</html>
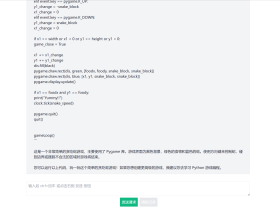
在上面的示例中,使用了浏览器内置的 fetch API 来获取指定网页的内容,并将获取到的文本显示在页面上。这是一个常见的做法,用于获取网页数据进行展示或进一步处理。
请注意,这种操作应该是在合法和道德的前提下进行的,遵循网站的使用条款,并尊重网站的隐私和权利。如果你要进行更复杂的操作,比如需要解析 HTML 内容,你可能需要使用额外的库来处理 HTML 解析。
- 我的微信
- 这是我的微信扫一扫
-


- 我的微信公众号
- 我的微信公众号扫一扫
-