- A+
摘要
上一篇博客跟大家详细介绍了如何写出《黄焖鸡米饭是怎么火起来的》这样的数据分析类的文章,相信很多人都对数据来源也就是如何爬取到黄焖鸡米饭商家信息很感兴趣。那么今天我就跟大家具体讲一讲怎么使用神箭手云爬虫写爬虫,以上篇博客的黄焖鸡米饭的代码为例。
首先我们先看一下这段从大众点评网上爬取黄焖鸡米饭商户信息的脚本代码:
// 大众点评上爬取所有"黄焖鸡米饭"的商户信息
var keywords = "黄焖鸡米饭";
var scanUrls = ["http://www.dianping.com/search/keyword/1/0_"+keywords];
//国内的城市id到2323,意味着种子url有2323个
//作为sample,这里改成1,只爬取上海的黄焖鸡米饭门店
//for (var i = 1; i <= 2323; i++) {
for (var i = 1; i <= 1; i++) {
scanUrls.push("http://www.dianping.com/search/keyword/"+i+"/0_"+keywords);
}
var configs = {
domains: ["dianping.com"],
scanUrls: scanUrls,
helperUrlRegexes: ["http://www.dianping.com/search/keyword/\\d+/0_.*"],
contentUrlRegexes: ["http://www.dianping.com/shop/\\d+/editmember"],
enableProxy: true,
interval: 5000,
fields: [
{
name: "shop_name",
selector: "//div[contains(@class,'shop-review-wrap')]/div/h3/a/text()"
},
{
name: "id",
selector: "//div[contains(@class,'shop-review-wrap')]/div/h3/a/@href"
},
{
name: "create_time",
selector: "//div[contains(@class,'block raw-block')]/ul/li[1]/span"
},
{
name: "region_name",
selector: "//div[@class='breadcrumb']/b[1]/a/span/text()",
required: true
},
{
name: "province_name",
selector: "//div[@class='breadcrumb']/b[1]/a/span/text()"
}
]
};
configs.onProcessHelperUrl = function(url, content) {
var urls = extractList(content, "//div[@class='tit']/a[not(contains(@class,'shop-branch'))]/@href");
for (var i = 0; i < urls.length; i++) {
addUrl(urls[i]+"/editmember");
}
var nextPage = extract(content,"//div[@class='page']/a[@class='next']/@href");
if (nextPage) {
addUrl(nextPage);
var result = /\d+$/.exec(nextPage);
if (result) {
var data = result[0];
var count = nextPage.length-data.length;
var lll = nextPage.substr(0, count)+(parseInt(data)+1);
addUrl(nextPage.substr(0, count)+(parseInt(data)+1));
addUrl(nextPage.substr(0, count)+(parseInt(data)+2));
}
}
return false;
}
configs.afterExtractField = function(fieldName, data) {
if (fieldName == "id") {
var result = /\d+$/.exec(data);
if (result) {
data = result[0];
}
}
else if (fieldName == "shop_name") {
if (data.indexOf("黄焖鸡米饭") == -1) {
skip();
}
}
else if (fieldName == "create_time") {
var result = /\d{2}-\d{2}-\d{2}$/.exec(data);
data = "20"+result[0];
}
else if (fieldName == "province_name" || fieldName == "region_name") {
var position = data.indexOf("县");
if (position != -1 && position < data.length -1) {
data = data.substr(0,position+1);
}
position = data.indexOf("市");
if (position != -1 && position < data.length -1) {
data = data.substr(0,position+1);
}
data = data.replace("餐厅","");
if (fieldName == "province_name") {
data = getProvinceNameByRegion(data);
}
}
return data;
}
start(configs);
可能不懂技术的童鞋表示看不懂,没关系,其实大部分都是一些基本的配置项(比如入口url啊,内容页url啊之类的,具体细节请参考上一篇博客)。现在我就跟大家具体讲一讲怎么在神箭手上运行这段爬虫代码:
1、打开浏览器,输入并打开:http://www.shenjianshou.cn/。
2、登录进入后台。
3、点击后台的“爬虫模板编写”->“新建爬虫模板”。首次进入的开发者需要先申请成为开发者,官方审核速度很快。

4、将代码拷贝到模板脚本里,点击“保存”。
5、点击左侧菜单栏里的“我的任务”->“创建爬虫任务”。
6、选择刚编写的模板后保存,跳转到任务页面后点击启动,等一段时间后爬取的结果就会显示在任务页面。
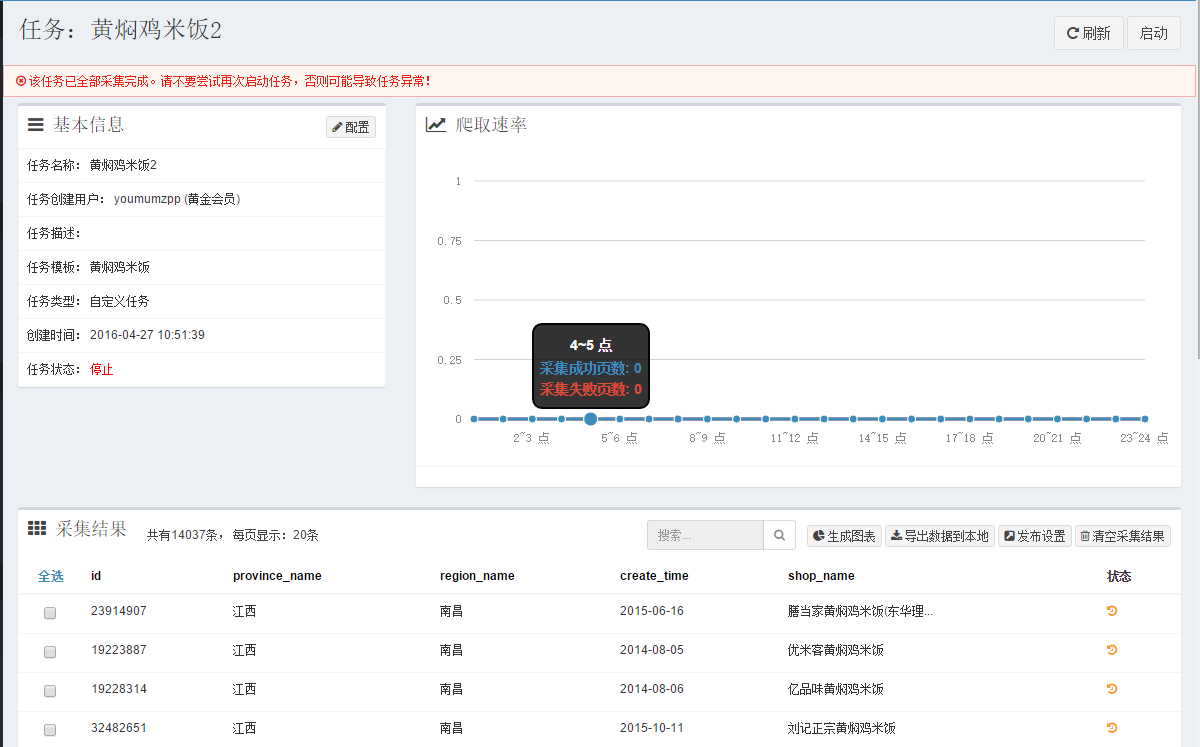
怎么样,很简单吧?想要爬取其他分类(比如大盘鸡啊重庆小面之类的)或者想要爬取其他网站也是没问题的,只需要更改一下爬虫代码就可以了。
from http://2879835984.iteye.com/blog/2297438
- 我的微信
- 这是我的微信扫一扫
-


- 我的微信公众号
- 我的微信公众号扫一扫
-






