- A+
所属分类:系统文档
无需高端显卡,无需复杂部署,用官方API免费调用业界领先的大语言模型。
在众多大模型服务中,英伟达平台提供了独特的价值:
- 完全免费:无需付费即可调用,无隐藏消费
- 模型丰富:聚合多个顶尖模型,包括最新的GLM-4.7、DeepSeek-V3.2等
- 开发者友好:标准OpenAI API兼容,极低学习成本,最重要国内可以直接调用。
- 无需硬件:云端调用,不依赖本地算力
注册与配置:5分钟快速开始
1. 账号注册流程
第一步:访问平台
打开英伟达NIM平台官网:https://build.nvidia.com,点击右上角"Login"或"Sign In"。(注意:通过魔法访问国外网站,直接登录会转到国内)
第二步:账户创建
支持三种注册方式:
- 推荐:GitHub账号一键登录
- 备用:Google账号登录
- 备选:邮箱注册(需验证码确认)
第三步:关键验证
完成基础注册后,点击右上角"Verify"进行手机号验证:
- 国家选择"China (+86)"
- 输入11位手机号码
- 接收并填写验证码
- 如遇收不到验证码,可尝试切换网络或更换手机号,我移动号接收不到,换电信号就可以正常接收。
2. 获取API密钥
验证成功后,获取API密钥:
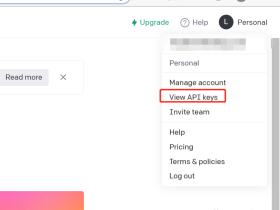
1. 点击右上角用户头像 → 选择"API Keys"
2. 点击"Generate API Key"
3. 命名Key(如"my-first-key")
4. 设置过期时间:建议选择"Never Expires"
5. 立即复制并妥善保存!格式为:nvapi-xxx_xxx重要提示:API密钥只在生成时显示一次,请务必立即保存。
模型概览:各显神通的免费模型阵容
| 模型名称 | 模型ID | 核心优势 | 适用场景 |
|---|---|---|---|
| GLM-4.7 | z-ai/glm4.7 | 中文能力强,代码生成优秀 | 中文对话、编程助手、文本创作 |
| MiniMax M2.1 | minimaxai/minimax-m2.1 | 响应速度快,多模态支持 | 快速问答、原型开发 |
| DeepSeek V3.2 | deepseek-ai/deepseek-v3.2 | 编程能力突出,逻辑清晰 | 代码生成、算法解析、技术问答 |
| Llama 3.1 70B | meta/llama-3.1-70b-instruct | 英文通用能力强 | 英文内容处理、学术研究 |
| Kimi K2 | moonshotai/kimi-k2-thinking | 长文本处理出色 | 文档分析、长文总结 |
注:各模型在nvidia平台的上下文长度多为128K,GLM-4.7支持200K,满足大多数需求。

三种调用方式:从新手到开发者全覆盖
方法一:Python API调用(开发者推荐)
from openai import OpenAI
import os
# 配置客户端
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1", # 固定地址
api_key=os.getenv("NVIDIA_API_KEY", "nvapi-xxx_xxx") # 替换为你的Key
)
def query_nim_model(prompt, model="z-ai/glm4.7", max_tokens=1024):
"""
调用英伟达NIM大模型
参数:
prompt: 用户输入的提示词
model: 模型ID,默认为GLM-4.7
max_tokens: 最大输出长度
返回:
模型生成的文本
"""
try:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.7, # 控制随机性,0-1之间
max_tokens=max_tokens,
stream=False # 设为True可流式输出
)
return response.choices[0].message.content
except Exception as e:
return f"调用失败: {str(e)}"
# 使用示例
if __name__ == "__main__":
result = query_nim_model("用Python写一个快速排序算法,并添加详细注释")
print(result)方法二:客户端工具(非开发者友好)
推荐工具:
- Cursor:智能IDE,内置AI助手功能
- Chatbox:开源ChatGPT风格客户端
- Cherry Studio:专为API调用设计的轻量级工具
以Chatbox为例的配置步骤:
- 下载安装Chatbox
- 点击"设置" → "模型提供商"
- 添加自定义提供商:
- 名称:NVIDIA NIM
- API地址:https://integrate.api.nvidia.com/v1
- API密钥:粘贴你的nvapi-xxx_xxx
- 创建对话,选择模型如"z-ai/glm4.7"
- 开始使用
方法三:在线体验(零配置)
访问 https://build.nvidia.com/explore/discover
- 选择任意模型
- 直接在网页对话框中提问
- 适合快速测试模型能力
实战示例:常见使用场景
场景1:代码助手
模型:DeepSeek V3.2 (模型ID: deepseek-ai/deepseek-v3.2)
提示词:实现一个Python函数,接收URL列表,异步获取所有页面的标题,要求添加错误处理和超时机制场景2:中文内容创作
模型:GLM-4.7 (模型ID: z-ai/glm4.7)
提示词:为一款智能水杯撰写三篇小红书风格的推广文案,突出其健康提醒和温度控制功能,每篇200字左右场景3:技术文档分析
模型:Kimi K2 (模型ID: moonshotai/kimi-k2-thinking)
提示词:分析以下API文档(上传文档),总结出关键端点、认证方式和速率限制重要参数详解
# 完整API调用参数示例
response = client.chat.completions.create(
model="z-ai/glm4.7", # 必填,模型标识
messages=[ # 必填,对话历史
{"role": "system", "content": "你是一个资深Python开发专家"},
{"role": "user", "content": "解释Python的装饰器原理"}
],
temperature=0.7, # 随机性:0-2,越高越有创意
max_tokens=2048, # 最大输出长度
top_p=0.9, # 核采样:0-1,控制多样性
stream=False, # 是否流式输出
presence_penalty=0.0, # 话题新鲜度:-2到2
frequency_penalty=0.0 # 重复惩罚:-2到2
)避坑指南:常见问题与解决方案
1. 调用频率限制
- 限制:每分钟40次请求(40 RPM)
- 应对:合理设计请求间隔,批量处理时添加延迟
- 错误处理:遇到429错误时,等待60秒后重试
2. 网络连接问题
# 添加重试机制的示例
import time
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
def robust_query(prompt):
return query_nim_model(prompt)3. 模型选择建议
- 中文任务:首选GLM-4.7,备选MiniMax
- 编程任务:首选DeepSeek,备选GLM-4.7
- 英文任务:首选Llama 3.1 70B
- 长文档处理:首选Kimi K2,备选GLM-4.7
进阶技巧:提升使用效率
1. 批量处理优化
def batch_process(queries, model="z-ai/glm4.7", delay=2):
"""批量处理多个查询,避免频率限制"""
results = []
for i, query in enumerate(queries):
if i > 0 and i % 10 == 0:
time.sleep(60) # 每10个请求暂停1分钟
result = query_nim_model(query, model)
results.append(result)
time.sleep(delay) # 请求间基础间隔
return results2. 本地配置管理
# 将API密钥加入环境变量
# Linux/macOS
echo 'export NVIDIA_API_KEY="nvapi-xxx_xxx"' >> ~/.bashrc
source ~/.bashrc
# Windows (PowerShell)
[System.Environment]::SetEnvironmentVariable('NVIDIA_API_KEY','nvapi-xxx_xxx','User')免费政策说明
目前英伟达平台提供的免费调用是完全免费的,但需要注意:
- 无明确期限:官方未公布免费政策结束时间
- 可能调整:英伟达保留随时调整政策的权利
- 建议:重要项目考虑多平台备份,避免单点依赖
- 关注渠道:定期查看NIM平台公告获取最新信息
总结
英伟达平台为开发者和AI爱好者提供了一个零门槛、高质量的AI模型调用入口。通过本文的指南,你可以:
- ✅ 5分钟完成账号注册和配置
- ✅ 选择最适合你需求的模型
- ✅ 通过API、客户端或网页三种方式调用
- ✅ 避开常见的使用陷阱
- ✅ 在免费额度内最大化利用资源
无论是个人学习、原型开发还是小规模项目,这个免费资源都能显著降低你的AI应用开发门槛。现在就开始你的英伟达NIM之旅,探索大语言模型的无限可能。
注意:本文信息基于2026年1月英伟达NIM平台状态,具体细节可能随平台更新而变化,请以官方最新文档为准。
- 我的微信
- 这是我的微信扫一扫
-


- 我的微信公众号
- 我的微信公众号扫一扫
-