- A+
所属分类:系统文档
本文介绍了如何实现流式应答(stream)的 grpc 大模型服务。
介绍
使用 LangChain 可以很轻易地实现 大模型(llm)的流式应答(stream),其主要原理是实现 CallbackHandler 的 on_llm_new_token 方法。而如果要将该流式应答与 grpc 的 server streaming 结合起来,则需要对该 on_llm_new_token 方法内部进一步处理。
实现
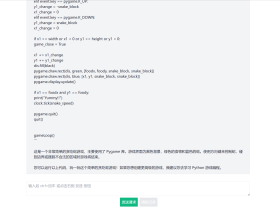
首先定义大模型,并规定其以 stream 形式作为应答(关于 LangChain 的使用方法,可自行参考官方文档):
main.py
from langchain import PromptTemplate, LLMChain
from langchain.chat_models import ChatOpenAI
# Fill your openai api key.
os.environ["OPENAI_API_KEY"] = ""
def init_llm() -> langchain.LLMChain:
"""设置支持 stream 的 llm,并返回对应的 chain"""
llm = ChatOpenAI(streaming=True, verbose=True, temperature=0.6)
# Get prompt template
template = ("""Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
{human_input}
Assistant:""")
chat_prompt = PromptTemplate(
input_variables=["human_input"],
template=template
)
# Construct Chain
chain = LLMChain(llm=llm, prompt=chat_prompt, callbacks=[], verbose=True)
return chain
假如我们的 grpc proto 通信协议定义如下:
chatgpt.proto
syntax = "proto3";
package openai;
service Chatgpt {
rpc Send(Message) returns (stream Answer) {}
}
message Message {
string content = 2;
Params params = 3;
}
message Answer {
string error = 1;
string content = 2;
}
message Params {
string model = 1;
float temperature = 2;
}
那么 grpc 的 server 端服务定义如下:
main.py
from callback import StreamingLLMCallbackHandler
# chatgpt_pb2_grpc、chatgpt_pb2 可根据 grpc 工具结合 proto 文件使用命令自动生成
from proto import chatgpt_pb2_grpc, chatgpt_pb2
class ChatgptService(chatgpt_pb2_grpc.ChatgptServicer):
def __init__(self, chain):
# 传入之前初始化的 chain
self.chain = chain
async def Send(self, request: chatgpt_pb2.Message, context: grpc.aio.ServicerContext):
# 在 grpc 响应时的响应结果转交给自实现的 StreamingLLMCallbackHandler 类中的 on_llm_new_token 方法
stream_handler = StreamingLLMCallbackHandler(context, chatgpt_pb2)
await self.chain.acall(
{"human_input": request.content},
callbacks=[stream_handler]
)
接下来就是实现 CallbackHandler 的 on_llm_new_token` 方法:
callback.py
from typing import Dict, Any, List, Union
import grpc.aio
from langchain.callbacks.base import AsyncCallbackHandler
from langchain.schema import LLMResult
from proto import chatgpt_pb2
class StreamingLLMCallbackHandler(AsyncCallbackHandler):
"""Callback handler for streaming LLM responses."""
def __init__(self, context: grpc.aio.ServicerContext, pb: chatgpt_pb2):
self.pb = pb
self.context = context
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> None:
"""Run when LLM starts running."""
async def on_llm_new_token(self, token: str, **kwargs: Any):
"""Run on new LLM token. Only available when streaming is enabled."""
# 当大模型响应返回 token 时,将 token 包裹成 grpc 的流式响应结构并写入到 grpc 响应流中
answer = self.pb.Answer(content=token)
await self.context.write(answer)
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
"""Run when LLM ends running."""
def on_llm_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> None:
"""Run when LLM errors."""
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
) -> None:
"""Run when chain starts running."""
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> None:
"""Run when chain ends running."""
def on_chain_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> None:
"""Run when chain errors."""
def on_tool_start(
self, serialized: Dict[str, Any], input_str: str, **kwargs: Any
) -> None:
"""Run when tool starts running."""
def on_tool_end(self, output: str, **kwargs: Any) -> None:
"""Run when tool ends running."""
def on_tool_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> None:
"""Run when tool errors."""
def on_text(self, text: str, **kwargs: Any) -> None:
"""Run on arbitrary text."""
在上面的 on_llm_new_token 方法体中,我们将大模型响应返回的 token 捕捉后加工成 grpc 需要的响应结构并返回。这其中主要使用了 grpc 的 context,它能让开发人员在通信过程中传递一些附带的值回去,也可用于传递身份信息、超时控制等。
在此留下一个疑问🙈,我总觉得这种实现方式不是太好,感觉对 grpc 通信的内部侵入过多,如果大家有更好的实现方式,欢迎一起交流。
总结
本文通过使用 grpc 的 context 和 langchain 的 stream 方法实现了 grpc 下的大模型流式应答服务,完整的代码可参考这里。
- 我的微信
- 这是我的微信扫一扫
-


- 我的微信公众号
- 我的微信公众号扫一扫
-