- A+
* 本文原创作者:whoamisb,本文属FreeBuf原创奖励计划,未经许可禁止转载
前言
这里主要是讲如何快速扫描到有问题的flash文件,用于批量,有时候很笨的方法也会有奇效,下面记录一下在实现过程中的一些思路和遇到的一些坑。

第三方flash插件
通过自己为数不多的网站渗透的经验,发现了两种存在xss的flash插件在国内的网站中比较普遍,一个是zeroclipboard.swf,一个是swfupload.swf,下面分别介绍下:
1、zeroclipboard.swf
主要的功能是复制内容到剪切板,中间由flash进行中转保证兼容主流浏览器,具体做法就是使这个透明的flash漂浮在复制按钮之上,下面给出xss poc代码:
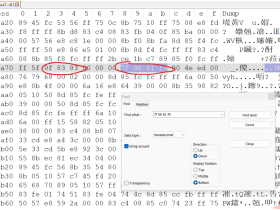
ZeroClipboard.swf?id=\%22))}catch(e){(alert)(/XSS/.source);}//&width=500&height=500原因显而易见,Externalinterface.call第二个参数传回来的id没有正确过滤导致xss
这里给出了漏洞前因后果,最后的修复其实很简单,将旧版本的
id = flashvars.id;下面加上这么一行代码
id = id.split("\\").join("\\\\");通过使用split()把字符串拆分成数组,再用join()拼接成字符串,把id参数中的所有”\”全部转义成”\\”,从而避免了输出点前面的引号被闭合,也就避免了执行后面的xss代码
具体漏洞原理在下面的漏洞实例里已经说的很清楚了
[腾讯实例教程] 那些年我们一起学XSS – 16. Flash Xss进阶 [ExternalInterface.call第二个参数]
通过多次手工的经验,列出如下可能存在ZeroClipboard.swf的payload目录
/ZeroClipboard.swf
/flash/ZeroClipboard.swf
/js/ZeroClipboard.swf
/swf/ZeroClipboard.swf
……
2、swfupload.swf
顾名思义,web文件上传组件
下面给出poc代码
swfupload.swf?movieName=aaa%22])}catch(e){(alert)(1)};//这里直接给出漏洞实例
[腾讯实例教程] 那些年我们一起学XSS – 15. Flash Xss进阶 [ExternalInterface.call第一个参数]
因为这个例子说的就是swfupload.swf,这里就不再赘述了,我们看一下github上的修复方法
Fixes a XSS issue in ExternalCalls.
多了这么一句
this.movieName = this.movieName.replace(/[^a-zA-Z0-9\_\.\-]/g, "");正则表达式中设置了 g(全局)标志,表示替换全部,意思就是将所有的[^a-zA-Z0-9\_\.\-]替换为空,’^'的意思是非,小写字母a-z,大写字母A-Z,数字0-9,再加上’_'、’.'、’-'这三个符号,扫描movieName参数的每个字符,只要一个字符不在上述的字符集里面,就删除掉,大白话就是这个意思
再列一下可能出现swfupload.swf的payload目录
/swfupload.swf
/swfupload/swfupload.swf
/upload/swfupload.swf
/images/swfupload.swf
/static/swfupload.swf
/common/swfupload.swf
……
设计思路
为了实现对上述两个swf文件的扫描,首先需要一个子域名列表,这里推荐两款,一个是seay的layer子域名挖掘机,字典比较全,速度比较慢;一个是lijijie的subDomainsBrute,字典比较小,速度比较快。看个人兴趣了,两款都能导出扫描结果到txt文件,这是我们需要的
根据手工成功的经验,两个swf文件一般都存在于web的静态资源目录里,这些个目录是我们需要找出来的,怎么找,找哪些,其实是一个取舍的过程,更多的是舍的过程
1、一舍子域名
放弃了https的子域名web,因为无法判断子域名是http或者https,如果全部判断两个,扫描时间double,不合算
home_page = "http://"+domain_name2、二舍访问页面
我这里的思路是只扫首页,把首页链接爬下来,整个网站的静态资源比如js文件,css文件,image文件的目录差不多都全了,然后提取目录与上面的payload拼接进行访问,其他页面出现的新的目录只能放弃,同时放弃的还有需要js跳转的首页
r = requests.get(home_page)3、三舍扫描链接
首页中扫描出的链接只取href,src,action后面的链接,而且放弃了解析js里面复杂的链接,只取正常的url进行访问,虽然知道可以通过Phantomjs之类的轻量级浏览器引擎做到,但是意义不大
link_list =re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=')|(?<=src=\").+?(?=\")|(?<=src=\').+?(?=')|(?<=action=\").+?(?=\")|(?<=action=\').+?(?=')" ,data)4、四舍访问时间
限制访问时间为3s,超时即继续下一个,防止线程卡死,这里的3s是根据我的网络速度设定的,网速快当然可以设小点
timeout=3下面是具体设计流程图
相关问题
没写过爬虫,一直是抱着边实践边修补的方法改善这个脚本,碰到的相关问题如下:
1、存在swf误报问题
如何判断是否存在flash文件,之前一直判断的是返回码200,误报比较严重。这里其实有两个坑,一个是用requests默认自动跳转,有些网站访问不存在的文件会跳转首页或者错误页面等,需要设置allow_redirects为False,比较简单。还有一个就是不管存不存在文件,都返回200的网站,这个只能判断响应包的内容了。通过对swf文件格式的研究,swf文件开头必为’cws’或者’fws’,这里的’cws’表示文件压缩,’fws’表示文件没有压缩。所以有代码如下:
if r.status_code == 200:
if b2a_hex(r.content[:3]) == "435753" or b2a_hex(r.content[:3]) == "465753":#CWS或者FWS
return True2、效率问题
单线程在跑,测试子域名比较少的时候还行,多了简直忍无可忍。一个子域名大约会产生100个链接,1个链接再拼接成10个payload链接,一个payload访问0-3s之间,经测试一个web大约需要100s左右的时间,几百个子域名的大厂商可以洗洗睡了。没有办法,加上多线程,幸好python多线程比较简单,几句话的事儿:
pool = ThreadPool(50)
results = pool.map(get_url_code, new_url_list)#get_url_code是requests.get封装
pool.close()
pool.join()3、无法建立新连接问题
查看出错信息发现出现了大量错误信息,格式差不多如下:
HTTPSConnectionPool(host='xxx.xxx.xxx', port=xxx): Max retries exceeded with url: /xxx/xxx (Caused by NewConnectionError(': Failed to establish a new connection: [Errno 11004] getaddrinfo failed',))http连接太多,无法建立新的连接?google一把,了解了个大概,requests使用了urllib3库,默认的http connection是keep-alive的,我们要做的就是把它关掉
requests.get("http://...", headers={'Connection':'close'})
requests.post("http://...", headers={'Connection':'close'})总结
说了这么多,其实出来的结果就是100多行python代码,测了几个大厂商的站,效果还行,就不知天高地厚地放出来了,接受批评和自我批评
作者微博地址:http://weibo.com/whoamisb
* 本文原创作者:whoamisb,本文属FreeBuf原创奖励计划,未经许可禁止转载